- 1 人工智能 ✅
- 1.1 人工智能 ✅
:LOGBOOK:
CLOCK: [2023-04-14 Fri 16:57:28]
:END:
- 什么是人工智能? “计算机控制”, “智能行为”,“类脑智能”
- >人工智能就是要让机器的行为看起来就像是人所表现出的智能行为一样。—— John McCarthy,1927-2011
- 诞生了一些流派,它们也可以互相融合:
- 连接主义,类脑智能,神经元连接,缺乏解释性
- 符号主义,知识和语义用符号来表示,能力不如连接主义。
- 行为主义,不断与环境交互
- 图灵是,测试促使人工智能从哲学探讨到科学研究的一个重要因素,引导了很多研究方向
- why?因为要使计算机通过图灵测试,它必须具有:
- 理解语言,感知(计算机视觉、语音信息处理、模式识别)
- 学习(机器学习,强化学习)
- 记忆(自然语言处理)
- 推理(知识代表)
- 决策(规划、数据挖掘)
- 等等能力
- why?因为要使计算机通过图灵测试,它必须具有:
- 什么是人工智能? “计算机控制”, “智能行为”,“类脑智能”
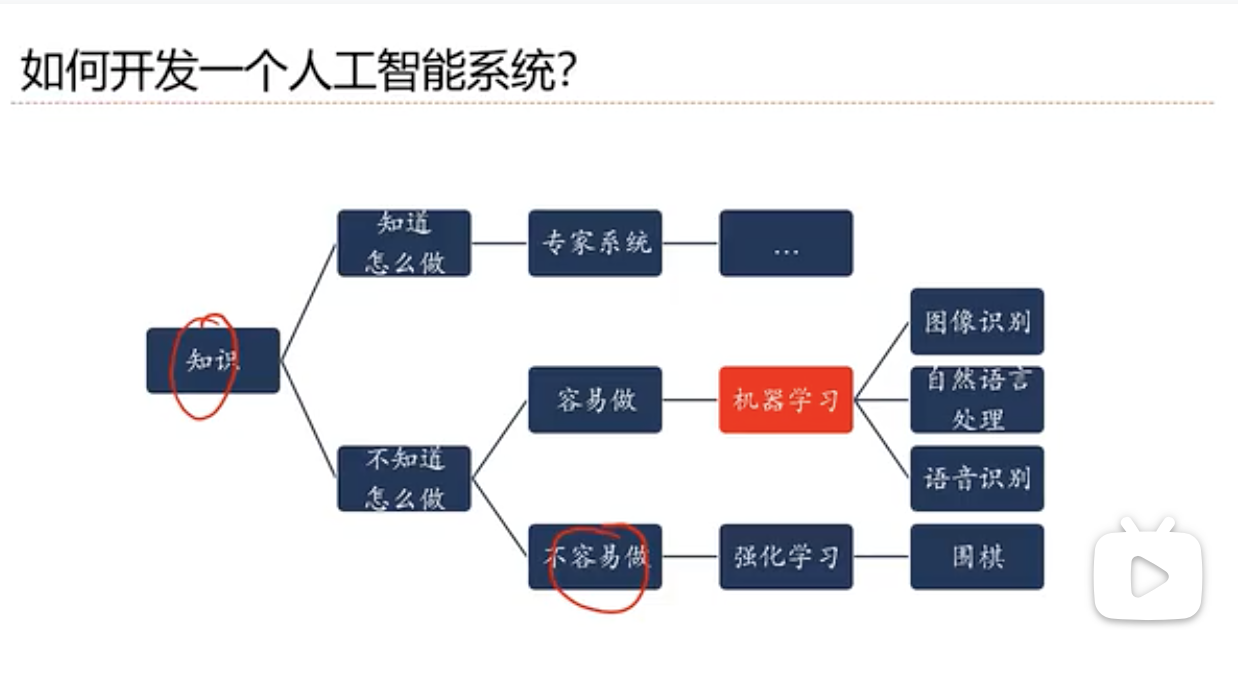
- 1.2 如何开发人工智能系统 ✅
- What’s the Rule? ⇒ 机器学习 ~= 映射函数 = 规则
- 例子:芒果机器学习

- 准备数据,随机:
- 特性(训练数据):颜色,大小,形状,产地,品牌,价格
- 芒果质量(输出变量)
- 学习
- 学习算法 ⇒ f(芒果特征) = 芒果质量
- 测试
- 非训练集数据,市场上。用学习算法预测好坏,验证
- What’s the Rule? ⇒ 机器学习 ~= 映射函数 = 规则
- 1.3 表示学习 ✅
- 机器学习
- 原始数据 → 数据预处理 → 特征提取 → 特征转换 → 预测 → 结果
- 数据预处理 → 特征提取 → 特征转换 = 特征处理
- 预测 = 浅层学习
- 特征工程(Feature Engineering)
- 浅层学习(Shallow Learning)
- 不涉及特征学习,主要靠人工经验或特征转换方法来抽取
- 语义鸿沟: 底层特征 VS 高层语义
- 原始数据 → 数据预处理 → 特征提取 → 特征转换 → 预测 → 结果
- 什么是好的数据表示:(Representation)?
- “好的表示” 是一个非常主观的概念,没有一个明确的标准
- 一般而言的几个优点:
- 具有很强的表示能力
- 使后续的学习任务变得简单
- 具有一般性,是任务或领域独立的
- 数据表示, 是机器学习的核心问题
- 表示形式: 如何在计算机中表示语义?
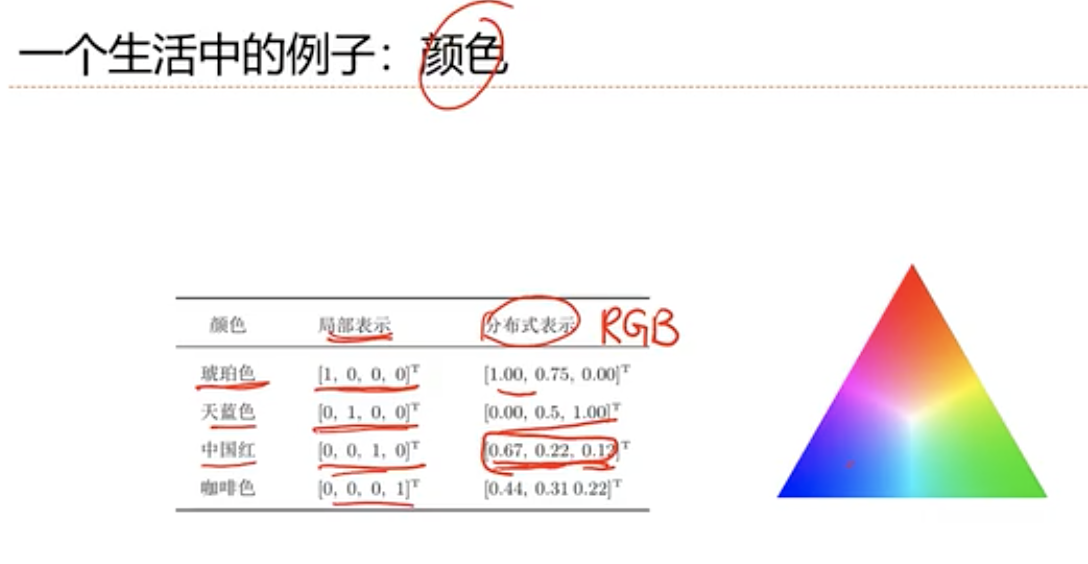
- 局部表示:
- 离散表示, 符号表示
- One-Hot 向量
- 分布式(distributed)表示
- 压缩,低维,稠密向量
- 用O(N)个参数表示O(2的k次幂)区间
- k为非零参数,k < N
- 局部表示:
- 传统的特征提取 VS 表示学习
- 特征提取: 基于任务或先验,去除无用特征
- 分布的, 对后续的分类器没有益处
- 表示学习: 通过深度模型,学习高层语义特征
- 从输入到输出,完整串联.
- 难点: 没有明确的目标
- 特征提取: 基于任务或先验,去除无用特征
- 一个好的表示学习策略,必须具备一定的深度
- 特征重用
- 指数级的表示能力
- 抽象表示与不变性
- 抽象表示需要多步的构造
- 特征重用
- 机器学习
- 1.4 深度学习(Deep Learning) ✅
- 深度学习的数学描述
-
#+BEGIN_EXPORT latex y = f(x) 浅层学习
#+END_EXPORT
-
#+BEGIN_EXPORT latex
y = f^2(f^1(x))
#+END_EXPORT
-
#+BEGIN_EXPORT latex
…
#+END_EXPORT
-
#+BEGIN_EXPORT latex y = f^5(f^4(f^3(f^2(f(x))))) 深度学习 #+END_EXPORT
-
f(x)为非线性函数,不一定连续。线性的线性还是线性,没意义
-
- 深度学习的数学描述
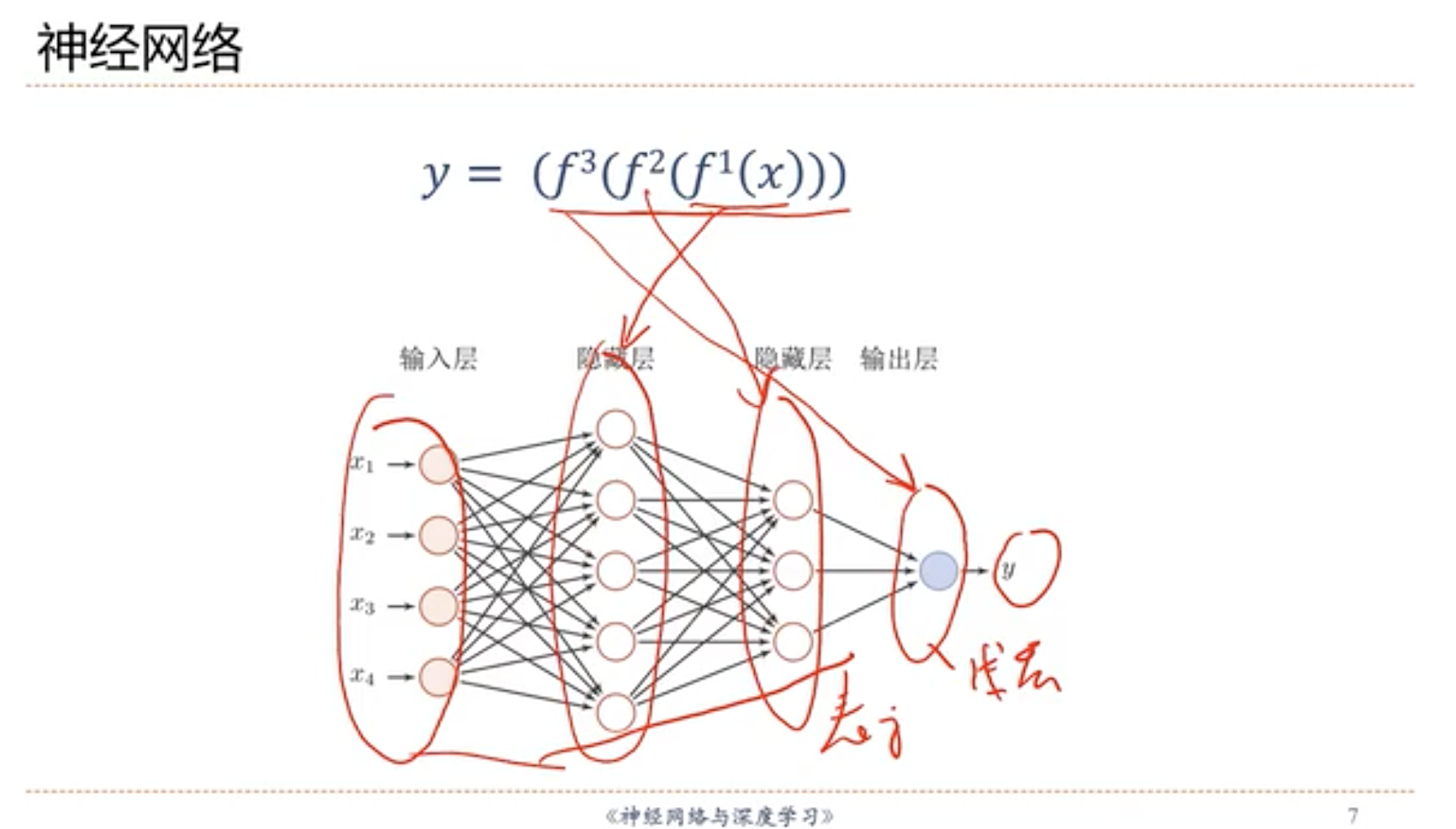
- 1.6 神经网络 ✅
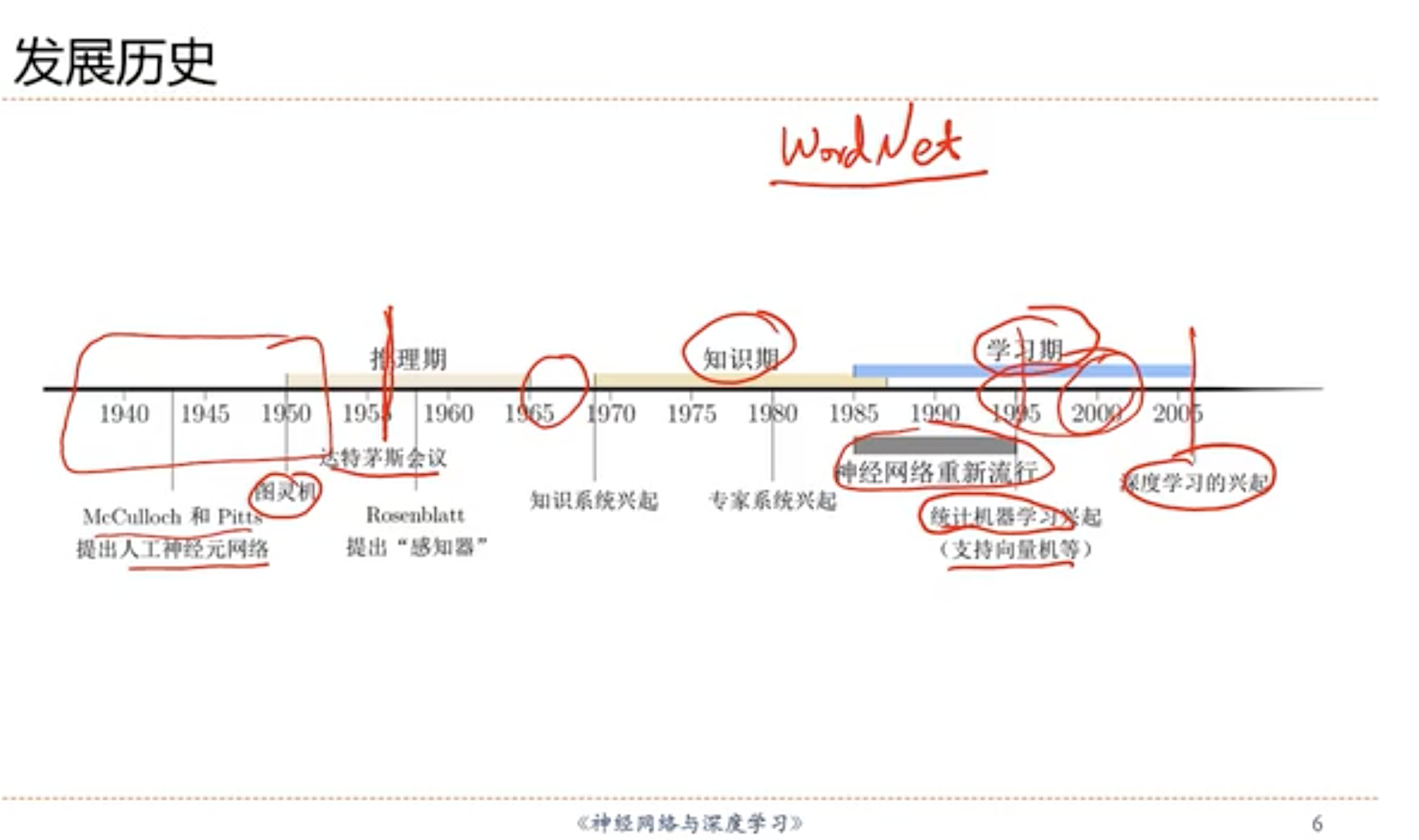
- 1.7 神经网络发展史(大致经历5个阶段) ✅
- 第一阶段:
- 第二阶段:
- 第三阶段:
- 第四阶段:
- 第五阶段:
- 第一阶段:
- 1.1 人工智能 ✅
:LOGBOOK:
CLOCK: [2023-04-14 Fri 16:57:28]
:END:
- 2 机器学习概述
- 2.1 关于概率的一些基本概念(基础)

- 概率(Probability)
- 随机变量(Random Variable)
- 离散随机变量(Bernoulli Distribution), 伯努利分散
- 二项分布(Binomial Distribution)
- 二项分布(Binomial Distribution)
- 连续随机变量
- 一般用 概率密度函数(probability density function,PDF),p(x)来描述
- 高斯分布 ( Gaussian Distribution),正态分布
- 随机向量
- 一组随机变量构成的向量
- 离散随机向量的 联合概率分布(Joint Probability Distribution)
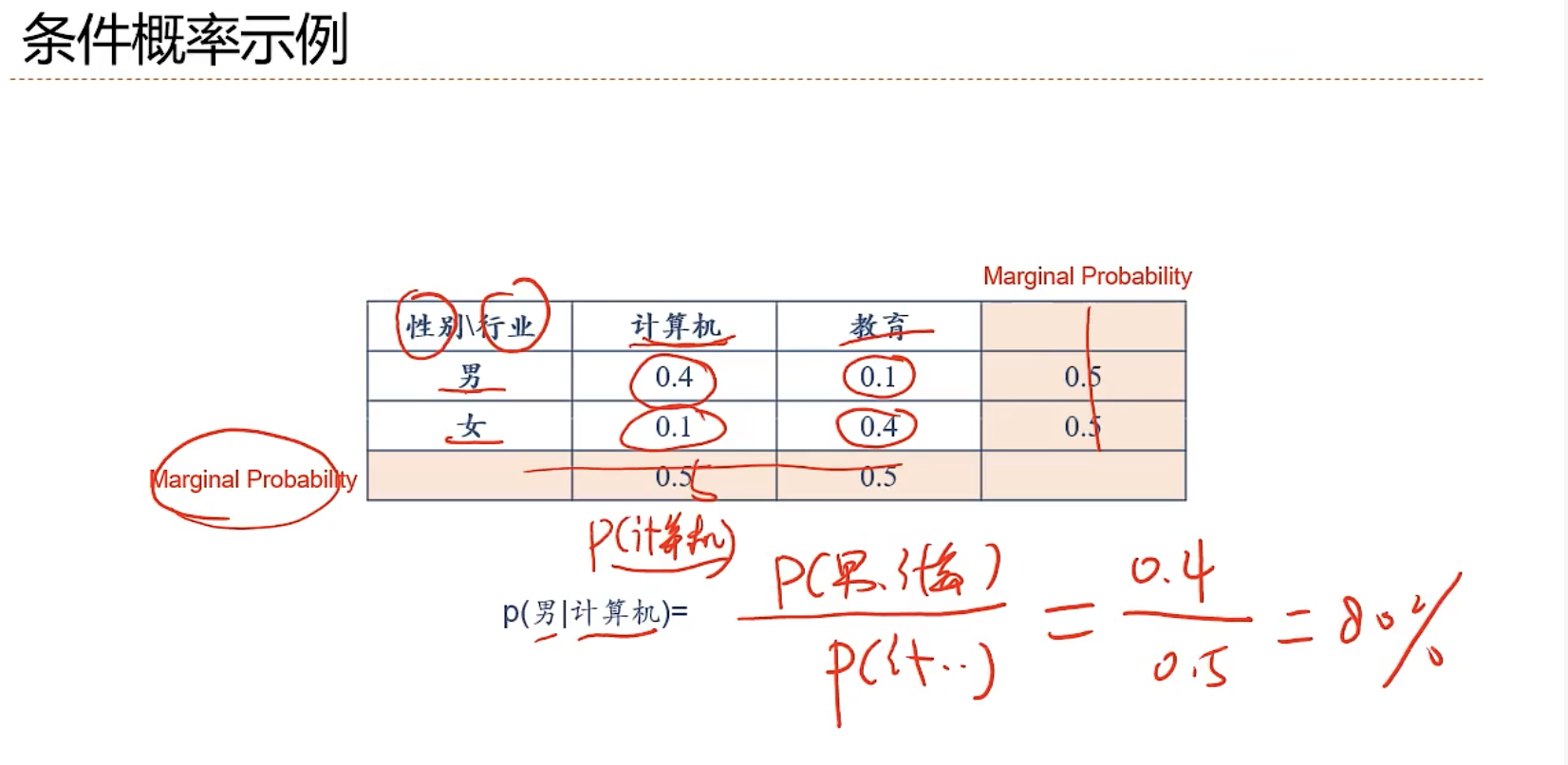
- 条件概率(Conditional Probability)
- 采样(Sampling)
- 给定一个概率分布,p(x),生成满足条件的样本
- 如何进行随机采样
- 直接采样
- 均匀分布 Uniform[0,1),Uniform[a,b) 随机数种子
- 离散分布
- 其他连续分布
- 逆变换采样(Inverse Transform Sampling)
- 直接采样
- 离散随机变量(Bernoulli Distribution), 伯努利分散
- 概率分布(Probability Distribution)
- 2.2 机器学习定义
- 2.3 机器学习类型
- 2.4 机器学习的要素
- 2.5 泛化与正则化(核心)
- 2.6 线性回归(具体例子 1)
- 2.7 多项式回归 (具体例子 2)
- 2.8 线性回归的概率视角
- 2.9 模型选择与“偏差-方差”分解
- 2.10 常用的定理
- 2.1 关于概率的一些基本概念(基础)
- 3 线性模型
- 3.1 分类问题示例
- 3.2 线性分类模型
- 3.3 交叉熵与对数似然
- 3.4 Logistic回归
- 3.5 Softmax回归
- 3.6 感知器
- 3.7 支持向量机
- 3.8 线性分类模型小结
- 4 前馈神经网络
- 4.1 神经元
- 4.2 神经网络
- 4.3 前馈神经网络
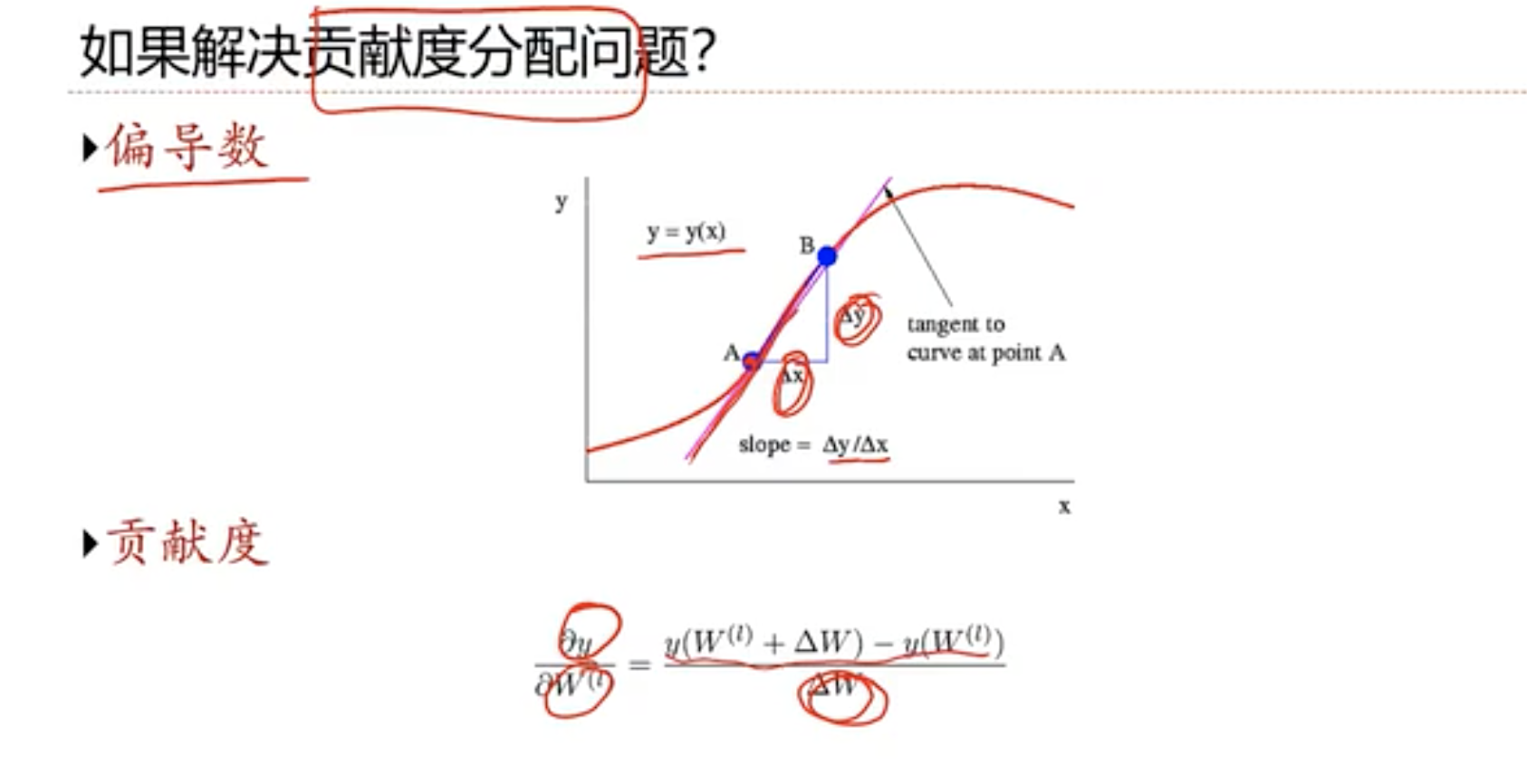
- 4.4 反向传播算法
- 4.5 计算图与自动微分
- 4.6 优化问题
- 5 卷积神经网络
- 5.2 卷积神经网络
- 5.3 其他卷积种类
- 5.4 典型的卷积网络
- 5.5 卷积网络的应用
- 5.6 应用到文本数据
- 6 循环神经网络
- 6.1 给神经网络增加记忆能力
- 6.2 循环神经网络
- 6.3 应用到机器学习
- 6.4 参数学习与长程依赖问题
- 6.5 如何解决长程依赖问题
- 6.6 GRU 与 LSTM
- 6.7 深层循环神经网络
- 6.8 循环网络应用
- 6.9 扩展到图结构
- 7 网络优化与正则化
- 7.1 神经网络优化的特点
- 7.2 优化算法改进
- 7.3 动态学习率
- 7.4 梯度方向优化
- 7.5 参数初始化
- 7.6 数据预处理
- 7.7 逐层规范化
- 7.8 超参数优化
- 7.9 网络正则化
- 7.10 暂退法(Dropout)
- 7.11 L1和L2正则化
- 7.12 数据增强
- 7.13 小结
- 8 注意力机制与外部记忆
- 8.1 注意力机制
- 8.2 人工神经网络中的注意力机制
- 8.3 注意力机制的应用
- 8.4 自注意力模型
- 8.5 Transformer
- 8.6 外部记忆
- 8.8 基于神经动力学的联想记忆
- 8.9 总结
- 9 无监督学习
- 9.1 聚类
- 9.2 K均值方法
- 9.3 层次聚类
- 9.4 (无监督)特征学习
- 9.5 主成分分析
- 9.6 编码与稀疏编码
- 9.8 自监督学习
- 9.9 概率密度估计
- 9.10 非参密度估计
- 9.11 半监督学习